FusionCreator Offer
FusionFabric.cloud enables you to access data provided by financial institutions through APIs and datasets. In this section you are provided with an overview of the data offer. Throughout this section, the following icons are used with their meaning.
| Applications developed by you and other platform users. | |
| Core systems exposed on the platform. | |
| Third party data storage provider. | |
| FusionFabric.cloud platform. |
API Models
On FusionFabric.cloud you have access to a collection of curated APIs that adhere to a specific model, by the way the communication occurs between the clients and the resource servers. Here’s an overview of the various API models supported by FusionFabric.cloud.
API
|
 |
Service API
|
 |
API-associated Events
|
 |
SPI
|
 |
OAuth2 Protocol Flow
FusionFabric.cloud implements the OAuth 2.0 Authorization Framework. Therefore all the roles defined in RFC5749 - Section 1.1 are supported.
On FusionCreator you will find APIs and SPIs, the two major API models supported by FusionFabric.cloud. The main difference between them lies in how the OAuth2 roles are played.
Here’s an excerpt of the roles definitions, from RFC5749 - Section 1.1:
- Resource owner - An entity capable of granting access to a protected resource. When the resource owner is a person, it is referred to as an end-user.
- Resource server - The server hosting the protected resources, capable of accepting and responding to protected resource requests using access tokens.
- Client - An application making protected resource requests on behalf of the resource owner and with its authorization. The term “client” does not imply any particular implementation characteristics (e.g., whether the application executes on a server, a desktop, or other devices).
- Authorization server - The server issuing access tokens to the client after successfully authenticating the resource owner and obtaining authorization.
API
In the API model, you develop client applications that consume resources exposed by the APIs on the API Catalog.
The resource servers are implemented either by the core systems, or by FusionFabric.cloud that also acts as the authorization server.
The protocol flow for the FusionFabric.cloud APIs, depicted in the following diagram, is taken from RFC5749 - Section 1.2. The icons are placed to help you understand how the roles are played.
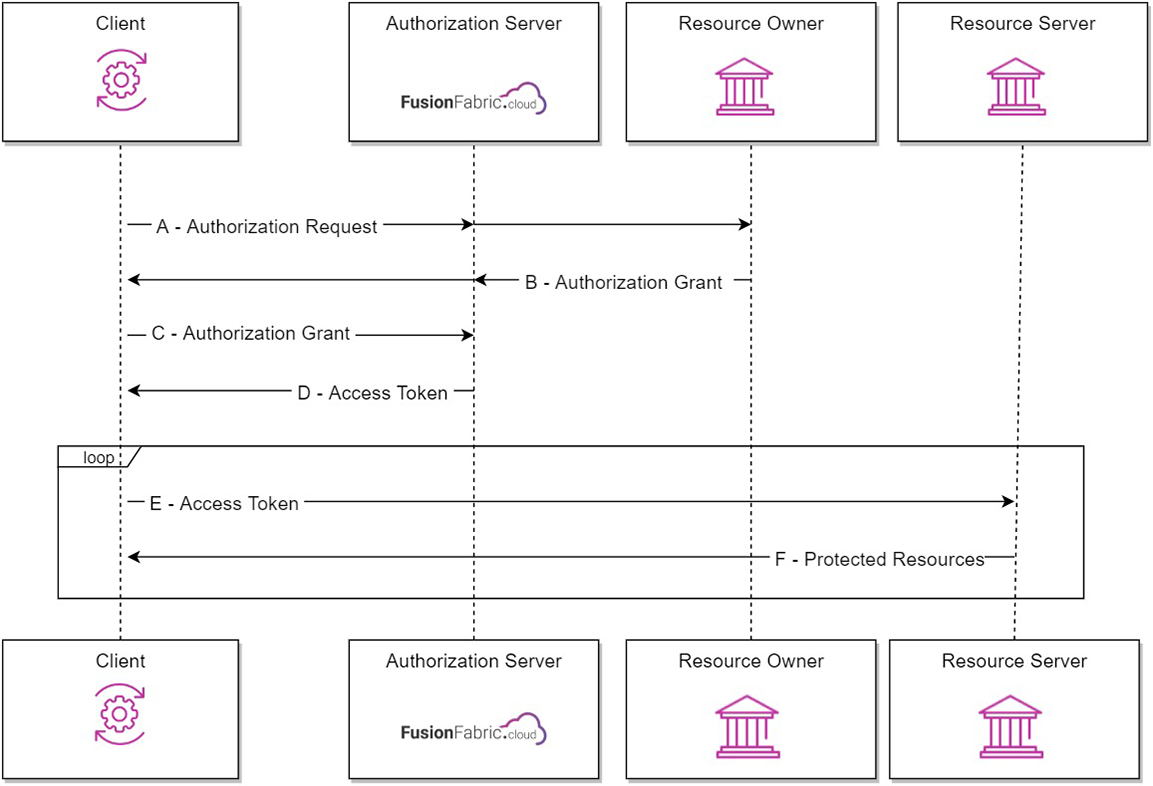
The API model.
SPI
In the SPI model, the roles are swapped, with respect to the API model. The SPIs are published by Finastra’s core systems on the API Catalog, and you must develop services that comply to the their specifications.
The core systems act as clients submitting synchronous requests to your services. Thus, you become a resource owner, and your services complement the core systems resources, extending their functionality.
The protocol flow for the FusionFabric.cloud SPIs, depicted in the following diagram, is taken from RFC5749 - Section 1.2. The icons are placed to help you understand how the roles are played.
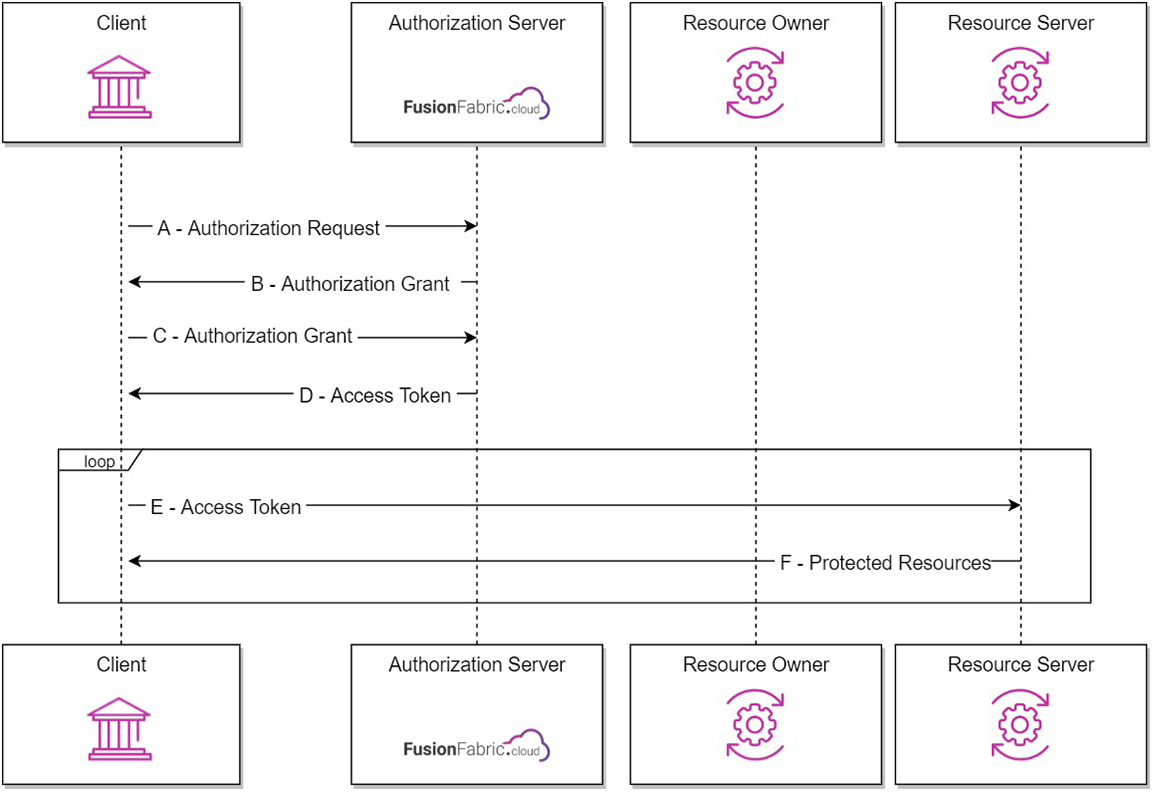
The SPI model.
To learn about the implementation workflow of an SPI, see the SPI Implementation Workflow section.
Datasets
As a FusionFabric.cloud partner, you have access to a collection of datasets.
A dataset represents a large chunk of data a financial institution shares with you.
In the following diagram, the communication flow for FusionFabric.cloud Datasets is depicted. Refer to the beginning of the section for the icon legend.
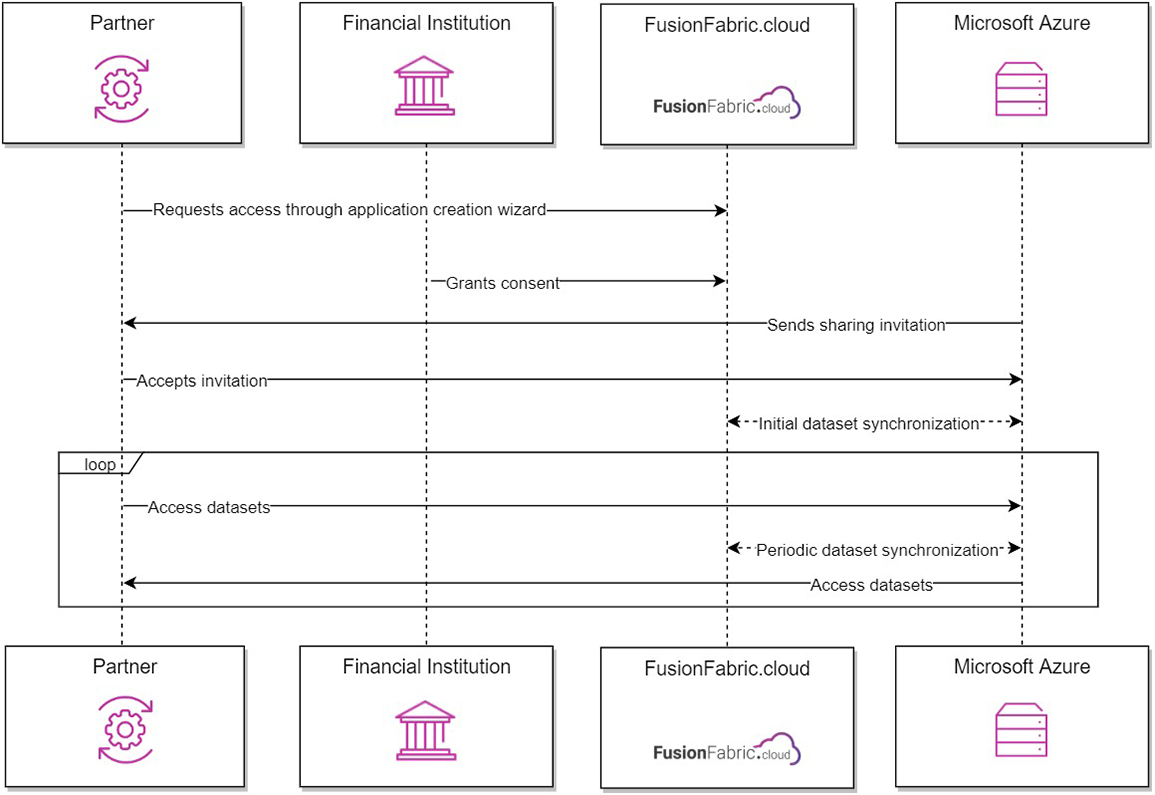
The communication flow model of Datasets.
To access the dataset, you need to have an Azure Account and attach a BlockBlobStorage to it.
For more information, read the Dataset Subscription section.
The datasets are stored using Microsoft Azure storage technology, such as Data Lake or BlobStorage, and are shared through Azure Data Share.
If you submit the email address, you will receive an invitation to the Azure Data Share. To accept and access the dataset, read the Azure Documentation.
If you have a service principal user, you can submit the Tenant ID and Object ID to receive the invitation to the Azure Data Share.
Once the dataset is added to your application, the relevant data is copied to your BlobStorage, using Azure Data Share.
In the development stage, a real-like sample dataset is provided.
Your BlobStorage is updated at the frequency rate you set in Azure Data Share, for the Received Shares. The maximum frequency rate is displayed on the dataset card and in the dataset overview page.
Encrypted Datasets
Some of the datasets available on FusionFabric.cloud contain encrypted data. You must decrypt the data before being able to use it for your business use case. Learn more about that from Dataset Decryption section.
Data Classification
Finastra has a wide range of requirements to protect the confidentiality, integrity and availability of data under its custody. Finastra protects data by applying safeguards and controls which are appropriate given the sensitivity and criticality of the data.
To classify the data there are two levels:
- Public data (for example Market data).
- Restricted data (the highest level), information that is protected under General Data Protection Regulation (GDPR) compliance or California Consumer Privacy ACT (CCPA).
For more information about GDPR/CCPA compliance please check General Data Protection Regulation guide and California Consumer Privacy Act.
You will have access to data, but the classification level enforces you to put in place appropriate policies to protect the privacy, compliant to GDPR or CCPA.
Restricted data represents the information provided to Finastra from the banks at business intelligence level. You must comply to regulations such as GDPR or CCPA when using the data in your apps.
Implication at API Call Level
The data classification tagging applies to API, endpoint and parameter level.
The tag is stored in the OpenAPI specification, in the x-finastra-data-classification field.
For example, in the following excerpt from the Account Information API, the x-finastra-data-classification field is added to the GET /accounts endpoint:
...
"/accounts": {
"get": {
"tags": ["Accounts"],
"summary": "Retrieve a Summary of Accounts for an Account Holder",
"operationId": "accounts",
"description": "This call returns a summary of all accounts owned by an account holder.",
"produces": ["application/json"],
"parameters": [...],
"responses": {...},
"x-finastra-data-classification": ["Restricted"]
}
},
...On the API reference documentation, you find information about the data classification first at API level.
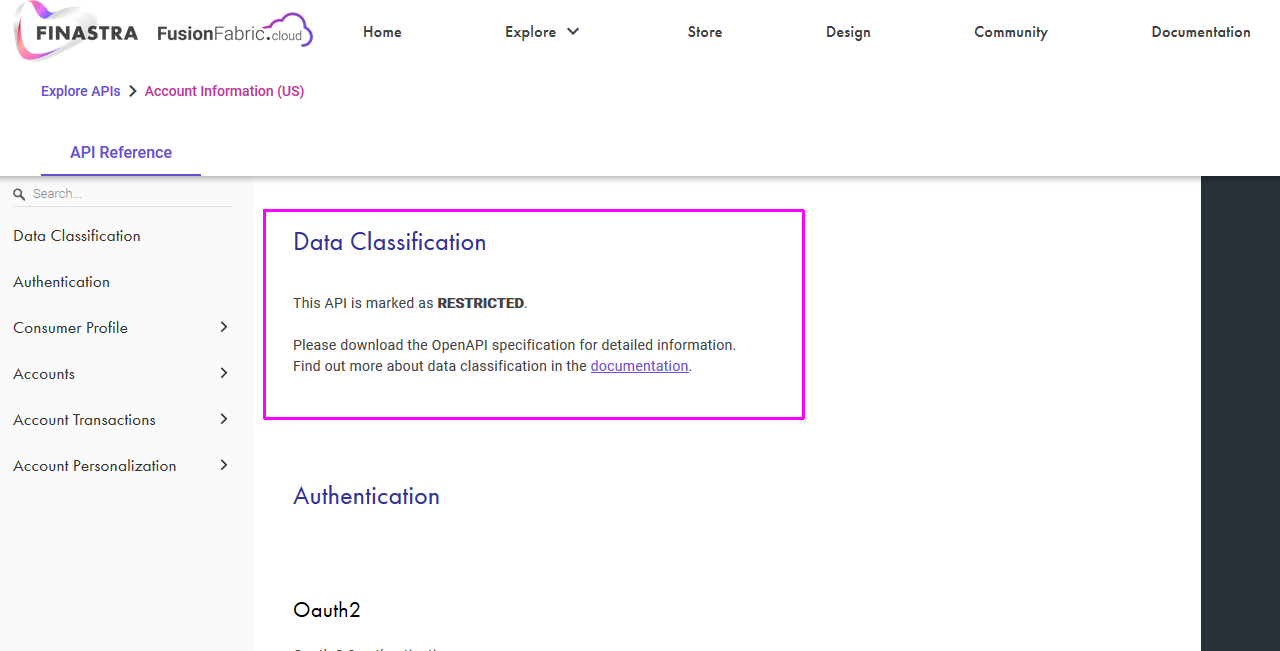
Data classification at API level, in the reference documentation.
You can also find information about the data classification at endpoint and field level marked with the Restricted label.
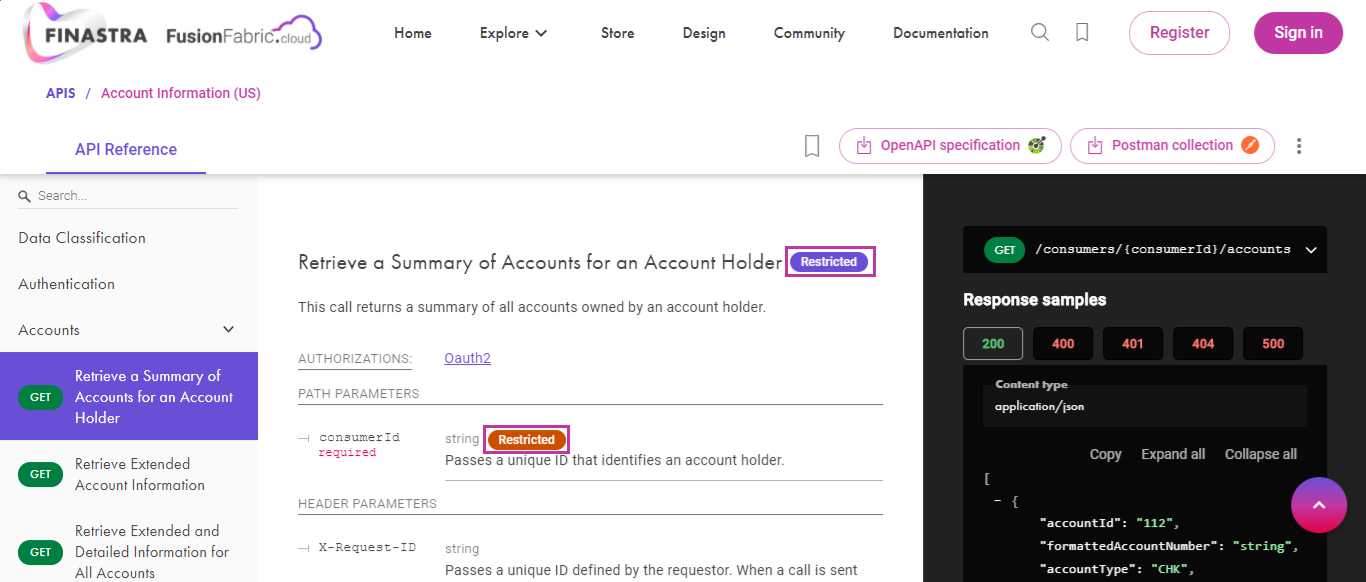
Data classification at API level, in the reference documentation.
Implication at Dataset Field Level
The data classification tagging applies to datasets, at field level.
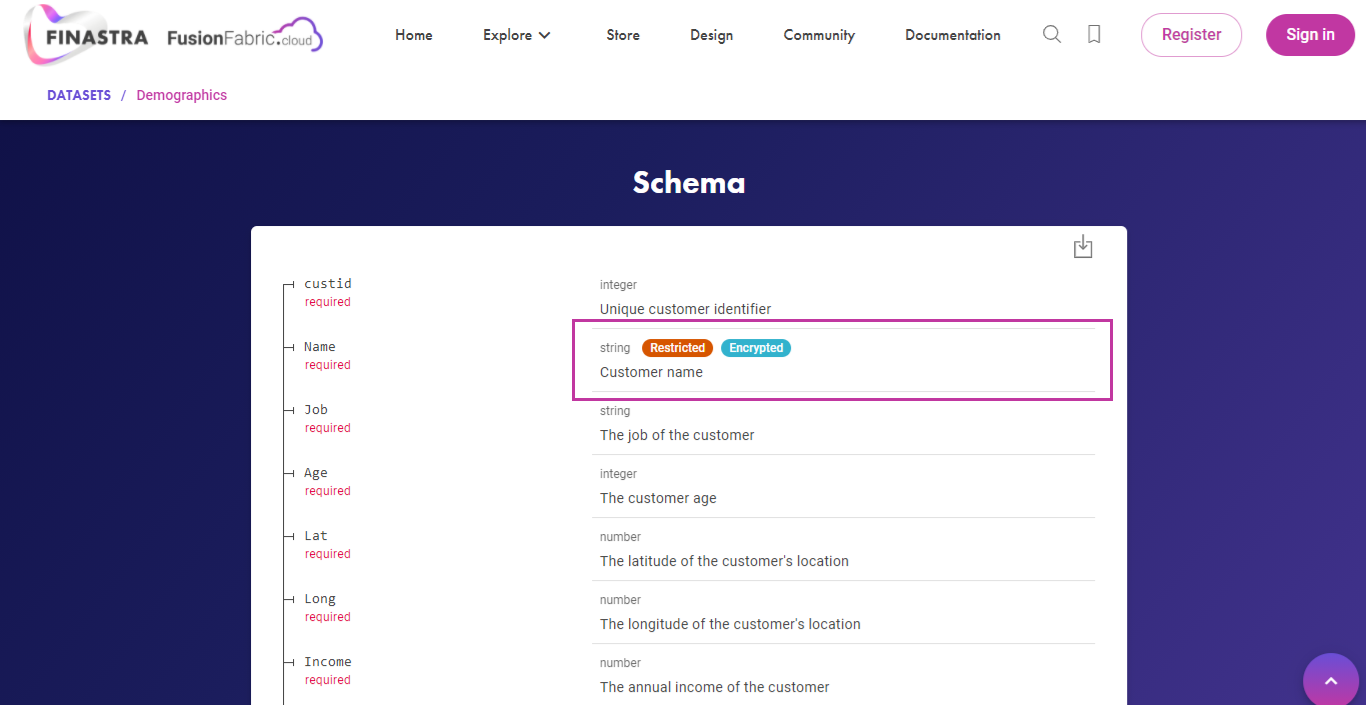
Data classification at dataset level, in the dataset schema.
The tag is stored in the dataset schema JSON file, in the x-finastra-data-classification field.
Data Handling
Data handling represents the way Finastra is managing the restricted data. The data handling tagging applies to datasets, at field level. The tag is stored in the dataset schema JSON file, in the x-finastra-data-handling field.
There are multiple methods used for data handling:
- Encryption
- Tokenization
- Masking
- De-identification
- Aggregation
For example, datasets might contain encrypted data. You must decrypt the data before using it.
For more information, check Dataset Decryption section
Inside the dataset schema, the data can be found marked with the following tags: restricted and encrypted (or other data handling method).
For example, in the following excerpt from the Demographics dataset, the x-finastra-data-classification and x-finastra-data-handling fields are added to the Name object:
...
"Name": {
"$id": "#/properties/Name",
"type": "string",
"description": "Customer name",
"x-finastra-data-classification": [
"Restricted"
],
"x-finastra-data-handling": [
"Encrypted"
]
},
...